두 집단의 평균을 비교할 때는 t-검정을 쓰지만, 집단이 3개 이상이 되면 분산분석이 필요합니다.
왜 t-검정을 여러 번 안 쓰고 ANOVA를 쓰는지, 그리고 분석 프로세스는 어떻게 되는지 상세히 알아봅시다
왜 t-검정 대신 ANOVA를 쓸까?
"A-B, B-C, A-C 이렇게 t-검정을 세 번 하면 안 되나요?"라는 의문이 생길 수 있습니다. 하지만 검정을 반복할수록 1종 오류(실제로는 차이가 없는데 차이가 있다고 결론 내릴 확률)가 커지는 문제가 발생합니다. 이를 방지하기 위해 전체 집단을 한 번에 비교하는 ANOVA를 사용합니다.
분산분석의 종류
- 일원 분산 분석(One-way ANOVA): 영향을 주는 요인(독립변수)이 1개일 때. (예: 약 종류에 따른 통증 완화 정도)
- 이원 분산 분석(Two-way ANOVA): 영향을 주는 요인이 2개일 때. (예: 약 종류와 성별에 따른 통증 완화 정도)
ANOVA를 수행하기 위한 3가지 필수 조건 (기본 가정)
ANOVA는 아무 데이터에나 막 쓰는 게 아닙니다.
다음 세 가지 조건이 충족되어야 신뢰할 수 있습니다.
- 독립성: 각 집단의 데이터는 서로 독립적이어야 합니다.
- 정규성: 각 집단의 데이터는 정규분포를 따라야 합니다. (Shapiro-Wilk 검정으로 확인)
- 등분산성: 모든 집단의 분산(데이터가 퍼진 정도)이 동일해야 합니다. (Levene 검정으로 확인)
분석 프로세스
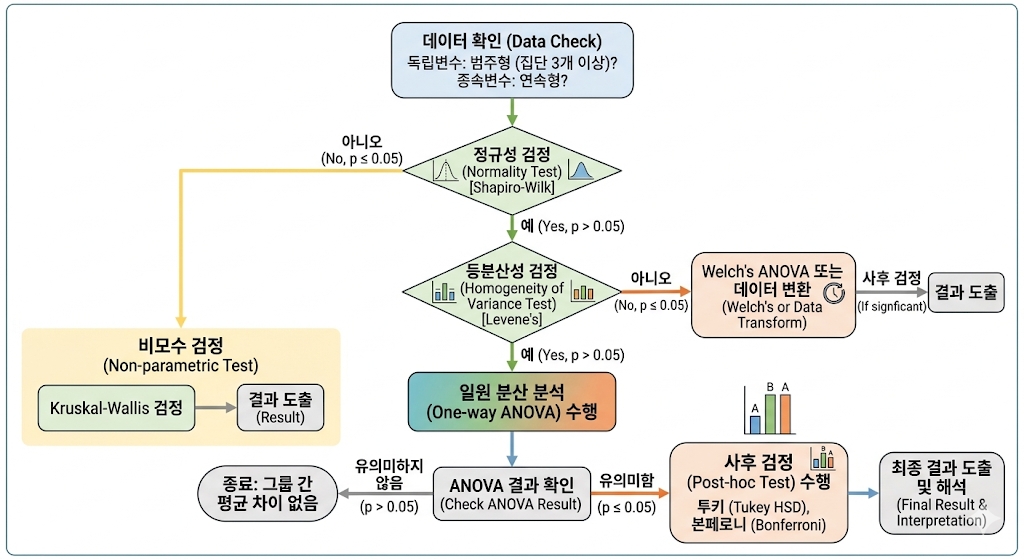
- 데이터 확인: 독립변수(범주형, 집단 3개 이상)와 종속변수(연속형) 확인
- 정규성 검정: shapiro 검정 수행
- 만약 정규성을 만족하지 않는다면? 비모수 검정인 Kruskal-Wallis 검정으로 바로 넘어갑니다.
- 등분산성 검정: levene 검정 수행
- ANOVA 시행: 정규성과 등분산성을 만족하면 ANOVA 수행
- 사후 검정(Post-hoc): ANOVA 결과 "차이가 있다(p < 0.05) "라고 나오면, 정확히 어떤 집단끼리 차이가 나는지를 확인하기 위해 수행합니다.
Python 코드 맛보기
일원 분산 분석
import pandas as pd
from scipy.stats import f_oneway, shapiro, levene
from statsmodels.formula.api import ols
from statsmodels.stats.anova import anova_lm
# 1. 정규성 검정 (p-value > 0.05 이면 만족)
print(shapiro(group1), shapiro(group2), shapiro(group3))
# 2. 등분산성 검정 (p-value > 0.05 이면 만족)
print(levene(group1, group2, group3))
# 3. ANOVA 수행 (방법 1: SciPy - 결과가 심플함)
f_stat, p_val = f_oneway(group1, group2, group3)
print(f'F-statistic: {f_stat}, p-value: {p_val}')
# 4. ANOVA 수행 (방법 2: Statsmodels - 아노바 테이블 출력, 더 선호됨)
model = ols('종속변수 ~ C(요인)', data=df).fit()
anova_table = anova_lm(model)
print(anova_table)
PR(>F): p-value입니다. 0.05보다 작으면 "집단 간 평균 차이가 유의미하다"라고 판단합니다.
이원 분산 분석 (Two-way ANOVA)
요인이 두 개일 때는 각 요인의 주 효과뿐만 아니라, 두 요인이 만나서 생기는 상호작용 효과를 확인하는 것이 핵심입니다.
- 상호작용 효과 p-value > 0.05: 두 요인은 독립적입니다.
- 상호작용 효과 p-value < 0.05: 두 요인이 서로 영향을 줍니다. (예: 특정 약이 남자에게는 효과가 좋고 여자에게는 별로인 경우)
# 상호작용을 포함한 모델 (C()는 범주형 변수임을 명시)
model = ols('종속변수 ~ C(요인1) * C(요인2)', data=df).fit()
print(anova_lm(model))사후 검정 (Post-hoc)
ANOVA에서 유의미한 결과가 나왔을 때만 수행합니다.
- Tukey(투키): 가장 일반적으로 사용되는 사후검정입니다.
- Bonferroni(본페로니): 비교 횟수가 많아질 때 1종 오류를 엄격하게 제어하고 싶을 때 사용합니다.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
# Tukey HSD 결과 확인
posthoc = pairwise_tukeyhsd(df['종속변수'], df['요인'], alpha=0.05)
print(posthoc)
# reject 컬럼이 True인 것들이 서로 유의미한 차이가 있는 집단입니다.
'AI' 카테고리의 다른 글
| 이원 분산 분석(Two-way ANOVA) (0) | 2026.05.14 |
|---|---|
| 일원분산분석( one-way ANOVA ) with python (0) | 2026.05.14 |
| 카이제곱 검정 (0) | 2026.05.11 |
| Qdrant + NCP Clova Embedding으로 AI 기반 매칭 시스템 구축하기 (2) | 2025.12.04 |